



































带你了解mapreduce

计算机编程是一门复杂的学问,但也不阻碍它仍有许多狂热追求者。在编程中,会有很多编程模型。编程模型,可以简单地理解为模板,遇到相似问题,程序员可以模板化解决,这样就减轻了程序员的工作负担。不同的编程环境和不同的应用对象,会有对应的不同的编程模型。今天我们来了解一下mapreduce这个编程模型,这是应用于大规模数据集群的并行运算。Map是映射,Reduce是化简。简单来说,这个模板的特性,是让不会分布式并行编程的人员,可以将程序运行在分布式系统上。
目录
1. 如何简单的理解mapreduce的应用
2. mapreduce的主要技术特征
3. mapreduce的其他技术特征
4. mapreduce和Spark的区别是什么
5. 初学mapreduce的常见问题
-
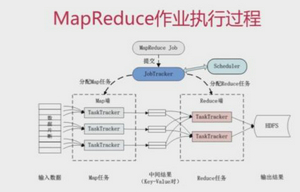
如何简单的理解mapreduce的应用
mapreduce的应用理念其实很简单,就是把一些数据先通过map(映射)进行归类,再通过reducer把同一类的数据进行化简处理。我们可以理解为,mapreduce是基于两个哲学原理设计的,大而化小和异而化同。接收到很多复杂数据,我们第一步就会先把数据分类,这就是异而化同。分类之后再进行细项分割,把数据切分成小块后,就可以并发或者批量处理了,这就是大而化小。map的工作就是分类数据,然后输出,reducer接收到的都是同类数据再进行分割处理。
-
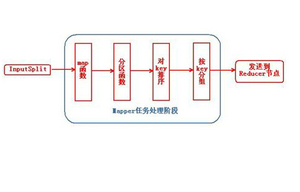
mapreduce的主要技术特征
在了解过mapreduce的功能后,我们来了解一下mapreduce设计技术都有什么主要特征。1、因为mapreduce需要进行大规模的数据处理,并由大量的数据出错需求,所以在集群的构建上,我们要选择低端的商用服务器,由外横向扩展。2、使用的是低端的商用服务器,所以节点硬件失效是很常见的,因此设计的时候要考虑到不影响服务质量的高容错计算系统,并且在节点失效后能够自动加入加群。3、mapreduce会采用就近原则,将无法计算的数据转移传输到就近可以计算的节点,而不仅限于数据的处理。
-
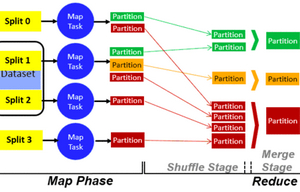
mapreduce的其他技术特征
除了刚才介绍的主要技术特征外,想要做好mapreduce设计,还要处理好以下三个方面。1、因为mapreduce需要大规模的处理数据,所以在内存中储存处理所有数据的难度很大,借助硬盘顺序访问处理的技术,可以大大提升处理速度。2、复杂度极高的编程其实对开发者的认知和判断造成了巨大的负担,而mapreduce要提供抽象机制,将程序员与系统层细节隔离开来,程序员仅需描述需要计算什么,具体如何计算可交由系统的执行框架处理。3、为了提升计算速度和数据处理规模,mapreduce的节点设计需要有很强的可扩展性。
-
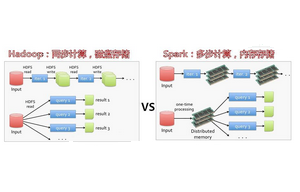
mapreduce和Spark的区别是什么
对于很多刚接触编程的人来说,通常会无法完全理解mapreduce和spark的应用区别。首先我们应该明确,mapreduce是分布式运算的编程框架,而Spark可以兼容HDFS、Hive等,可以融入hadoop的系统。这两者的区别,主要表现在:1.spark基于内存的运算,要比mapreduce快100倍,基于硬盘的运算,要比mapreduce快10倍。2.spark支持流式、离线运算,而mapreduce则只支持离线运算。3.mapreduce必须运行在资源系统上,而spark本身集成资源调度,可以运行在自身的Master、worker或者yarn上。
-

初学mapreduce的常见问题
不管怎样,想要真正学会、理解、应用一种编程方式,都不是容易的事情。对于mapreduce初学者来说,经常会问,mapreduce的输入源可以是视图吗?答案是,这是不可以的,只能是表,这样把结果写入到表或分区时,才会覆盖掉原有的数据。除此之外,初学者还应该了解到Mapper中输入的每条Record数据,可以按序号读取,也可以按照列名来获取record,但是reduce.setup不能读入输入表,只能读cache table。mapreduce在执行时,不可以调用shell文件,会被沙箱阻挡。如果还想要了解更多关于mapreduce的常见问题,建议初学者可以多看一些文档。





- 关于cms系统设计的小知识
- 中企动力提醒:网络违法案例,等保刻不容缓
- 中企动力:网站运营怎么做之统计后台篇
- 中企动力:网站运营难不难?
- 中企动力在5G时代给企业的小建议
- 中企动力:个人建站需要哪些能力?
- 中企动力:公司网站被黑怎么办?
- 中小企业数字经济论坛召开,中企动力助力企业数字化转型
- 中企动力:教你如何建立“新型”企业网站
- 肉驴养殖利润效益分析
- 在线建网站靠谱吗?在线建网站常问的5个问题!
- 营销广告人员必看,市场分析包括哪些方面?
- 揭秘:在线建网站内幕曝光,80%老板都被骗了
- 优秀的广告设计理念需要具备的基本要素
- 广告联盟的特点
- 数据库在建立信息管理系统中的特点
- 抖音和今日头条的关系浅析
- 你真的会写品牌推广计划吗?
- 你了解linux运维工程师吗
- 微信推广平台如何起到良好的宣传作用





